数据结构(2)线性结构
线性结构
线性数据结构是一种数据组织方式,其元素在一条线上依次排列。这些数据结构的特点是元素之间存在前后关系,每个元素都最多只有一个前驱和一个后继。在实际应用中,线性数据结构被广泛使用,如链表、栈和队列等。
栈
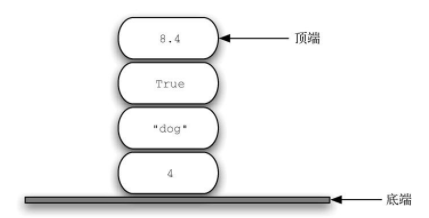
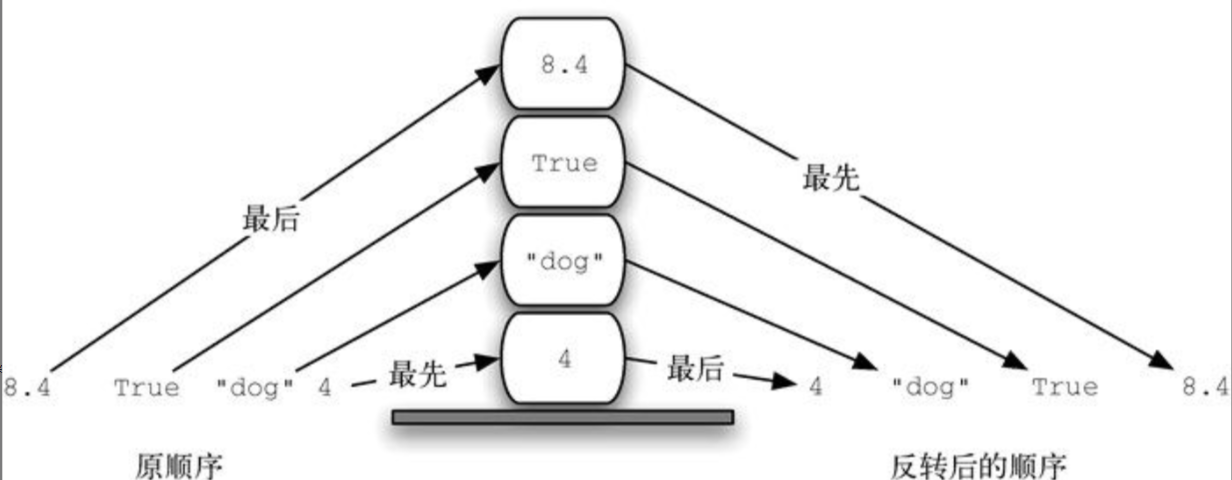
栈 有时也被称作“下推栈”。它是有序集合,添加操作和移除操作总发生在同一端,即“顶端”,另一端则被称为“底端”。
栈中的元素离底端越近,代表其在栈中的时间越长,因此栈的底端具有非常重要的意义。最新添加的元素将被最先移除。这种排序原则被称作LIFO (last-in first-out),即后进先出。它提供了一种基于在集合中的时间来排序的方式。最近添加的元素靠近顶端,旧元素则靠近底端。
栈通常用于程序中需要“临时”保存数据的操作,特别适用于递归算法的实现、表达式求值、程序调用信息(包括递归函数和中断处理)、内存分配、缓冲区管理和追溯操作等方面的应用。
抽象数据类型
Stack()创建一个空栈。它不需要参数,且会返回一个空栈。push(item)将一个元素添加到栈的顶端。它需要一个参数item,且无返回值。pop()将栈顶端的元素移除。它不需要参数,但会返回顶端的元素,并且修改栈的内容。peek()返回栈顶端的元素,但是并不移除该元素。它不需要参数,也不会修改栈的内容。isEmpty()检查栈是否为空。它不需要参数,且会返回一个布尔值。size()返回栈中元素的数目。它不需要参数,且会返回一个整数。
用python实现
1 | class Stack: |
应用
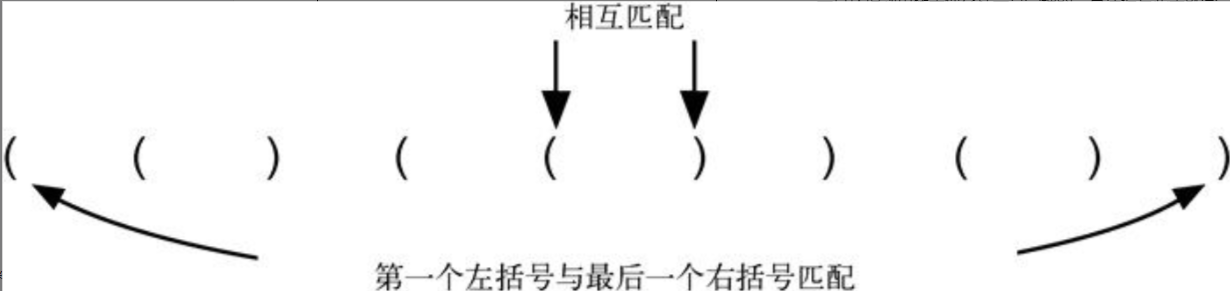
匹配括号
由一个空栈开始,从左往右依次处理括号。如果遇到左括号,便通过push 操作将其加入栈中,以此表示稍后需要有一个与之匹配的右括号。反之,如果遇到右括号,就调用pop 操作。只要栈中的所有左括号都能遇到与之匹配的右括号,那么整个括号串就是匹配的;如果栈中有任何一个左括号找不到与之匹配的右括号,则括号串就是不匹配的。在处理完匹配的括号串之后,栈应该是空的。代码清单3-3展示了实现这一算法的Python代码。
1 | from pythonds.basic import Stack |
将十进制转为二进制
divideBy2 函数接受一个十进制数作为参数,然后不停地将其除以2。第6行使用了内建的取余运算符% ,第7行将求得的余数压入栈中。当除法过程遇到0之后,第10~12行就会构建一个二进制数字串。第10行创建一个空串。随后,二进制数字从栈中被逐个取出,并添加到数字串的最右边。最后,函数返回该二进制数字串。
1 | from pythonds.basic import Stack |
队列
队列 是有序集合,添加操作发生在“尾部”,移除操作则发生在“头部”。新元素从尾部进入队列,然后一直向前移动到头部,直到成为下一个被移除的元素。
最新添加的元素必须在队列的尾部等待,在队列中时间最长的元素则排在最前面。这种排序原则被称作FIFO(first-in first-out),即先进先出,也称先到先得。
在日常生活中,我们经常排队,这便是最简单的队列例子。进电影院要排队,在超市结账要排队,买咖啡也要排队(等着从盘子栈中取盘子)。好的队列只允许一头进,另一头出,不可能发生插队或者中途离开的情况。图3-12展示了一个由Python数据对象组成的简单队列。

队列的ADT
Queue()创建一个空队列。它不需要参数,且会返回一个空队列。enqueue(item)在队列的尾部添加一个元素。它需要一个元素作为参数,不返回任何值。dequeue()从队列的头部移除一个元素。它不需要参数,且会返回一个元素,并修改队列的内容。isEmpty()检查队列是否为空。它不需要参数,且会返回一个布尔值。size()返回队列中元素的数目。它不需要参数,且会返回一个整数。
python实现
1 | class Queue: |
应用
双端队列
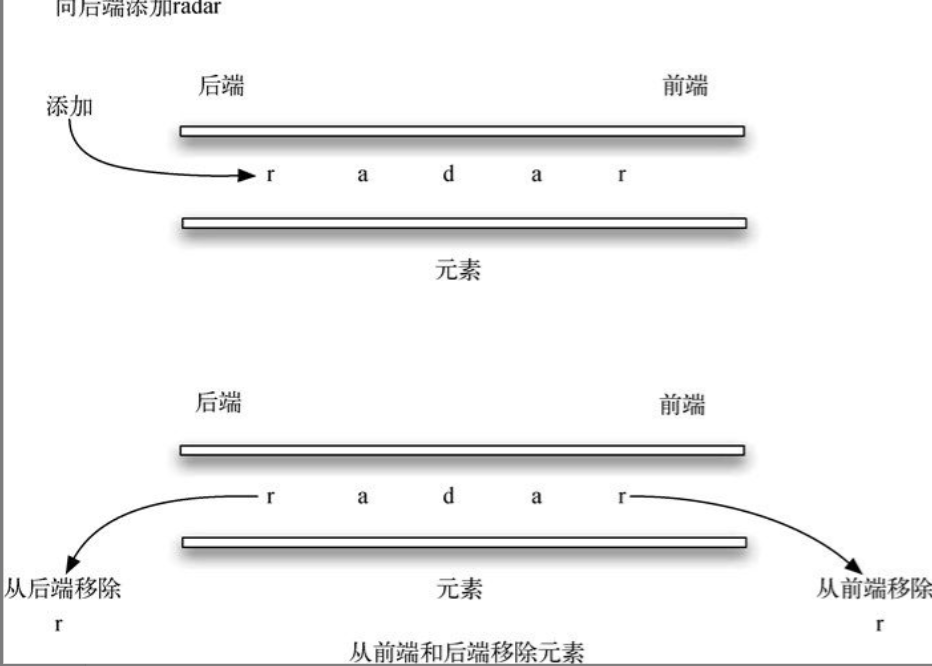
双端队列 是与队列类似的有序集合。它有一前、一后两端,元素在其中保持自己的位置。与队列不同的是,双端队列对在哪一端添加和移除元素没有任何限制。新元素既可以被添加到前端,也可以被添加到后端。同理,已有的元素也能从任意一端移除。某种意义上,双端队列是栈和队列的结合。图3-16展示了由Python数据对象组成的双端队列。
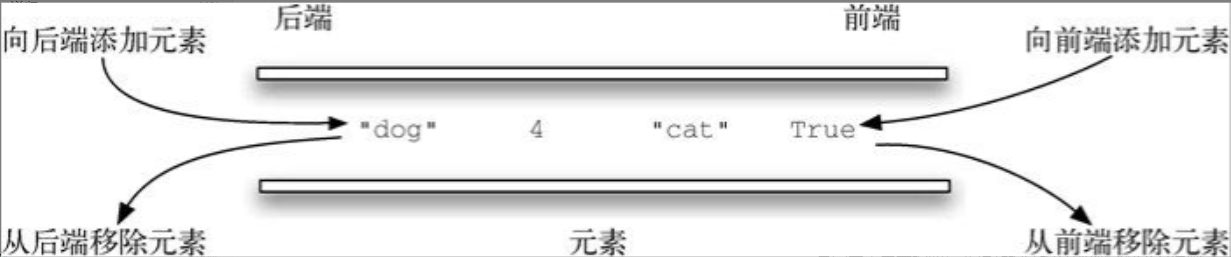
尽管双端队列有栈和队列的很多特性,但是它并不要求按照这两种数据结构分别规定的LIFO原则和FIFO原则操作元素。具体的排序原则取决于其使用者。
双端队列的ADT
Deque()创建一个空的双端队列。它不需要参数,且会返回一个空的双端队列。addFront(item)将一个元素添加到双端队列的前端。它接受一个元素作为参数,没有返回值。addRear(item)将一个元素添加到双端队列的后端。它接受一个元素作为参数,没有返回值。removeFront()从双端队列的前端移除一个元素。它不需要参数,且会返回一个元素,并修改双端队列的内容。removeRear()从双端队列的后端移除一个元素。它不需要参数,且会返回一个元素,并修改双端队列的内容。isEmpty()检查双端队列是否为空。它不需要参数,且会返回一个布尔值。size()返回双端队列中元素的数目。它不需要参数,且会返回一个整数。
python实现
1 | class Deque: |
应用
回文检测
使用一个双端队列来存储字符串中的字符。按从左往右的顺序将字符串中的字符添加到双端队列的后端。此时,该双端队列类似于一个普通的队列。然而,可以利用双端队列的双重性,其前端是字符串的第一个字符,后端是字符串的最后一个字符,由于可以从前后两端移除元素,因此我们能够比较两个元素,并且只有在二者相等时才继续。如果一直匹配第一个和最后一个元素,最终会处理完所有的字符(如果字符数是偶数),或者剩下只有一个元素的双端队列(如果字符数是奇数)。任意一种结果都表明输入字符串是回文。
1 | from pythonds.basic import Deque |
列表
并非所有编程语言都有列表。对于不提供列表的编程语言,程序员必须自己动手实现。
列表 是元素的集合,其中每一个元素都有一个相对于其他元素的位置。更具体地说,这种列表称为无序列表。可以认为列表有第一个元素、第二个元素、第三个元素,等等;也可以称第一个元素为列表的起点,称最后一个元素为列表的终点。为简单起见,我们假设列表中没有重复元素。
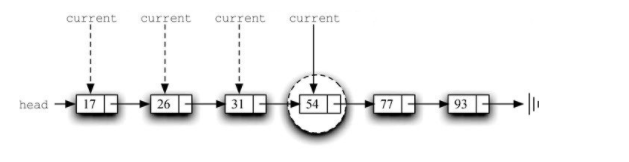
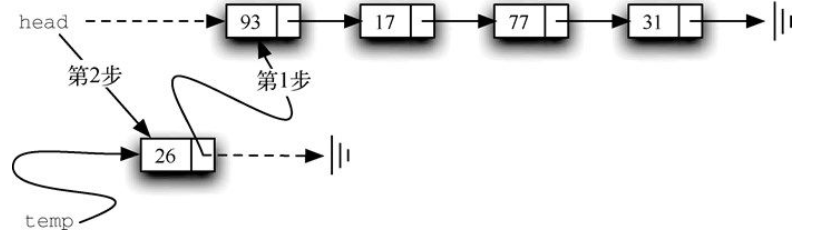
假设54, 26, 93, 17, 77, 31是考试分数的无序列表。注意,列表通常使用逗号作为分隔符。这个列表在Python中显示为[54, 26, 93, 17, 77, 31] 。
无序列表的ADT
List()创建一个空列表。它不需要参数,且会返回一个空列表。add(item)假设元素item之前不在列表中,并向其中添加item。它接受一个元素作为参数,无返回值。remove(item)假设元素item已经在列表中,并从其中移除item。它接受一个元素作为参数,并且修改列表。search(item)在列表中搜索元素item。它接受一个元素作为参数,并且返回布尔值。isEmpty()检查列表是否为空。它不需要参数,并且返回布尔值。length()返回列表中元素的个数。它不需要参数,并且返回一个整数。append(item)假设元素item之前不在列表中,并在列表的最后位置添加item。它接受一个元素作为参数,无返回值。index(item)假设元素item已经在列表中,并返回该元素在列表中的位置。它接受一个元素作为参数,并且返回该元素的下标。insert(pos, item)假设元素item之前不在列表中,同时假设pos是合理的值,并在位置pos处添加元素item。它接受两个参数,无返回值。pop()假设列表不为空,并移除列表中的最后一个元素。它不需要参数,且会返回一个元素。pop(pos)假设在指定位置pos存在元素,并移除该位置上的元素。它接受位置参数,且会返回一个元素。
python实现无序列表
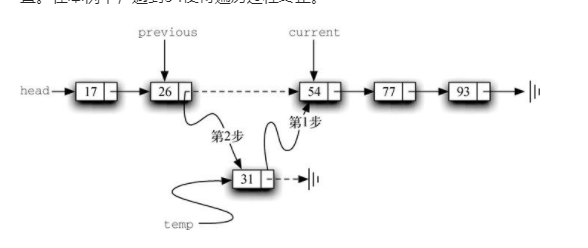
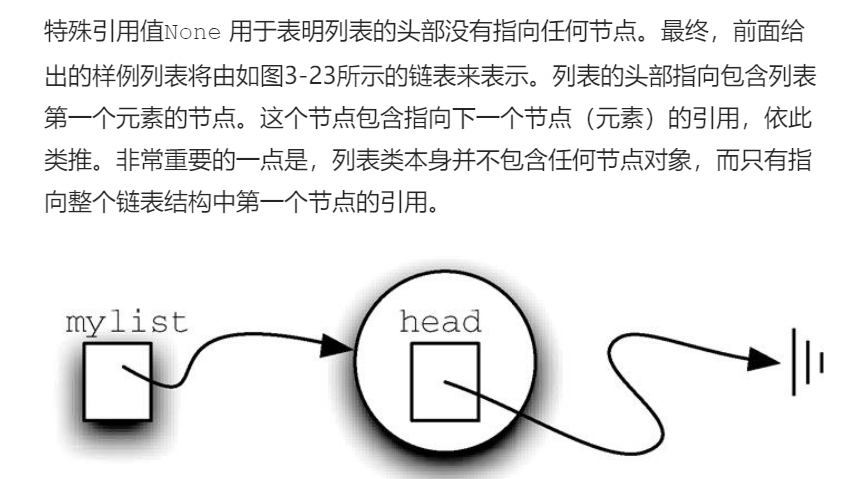
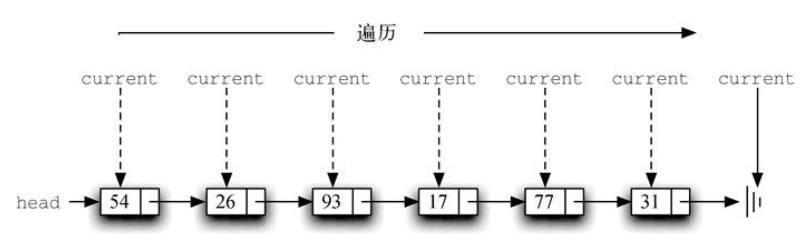
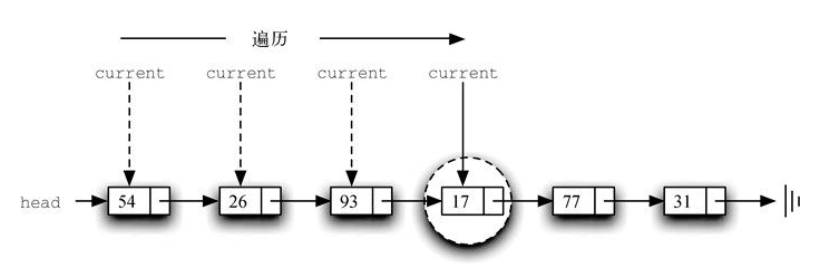
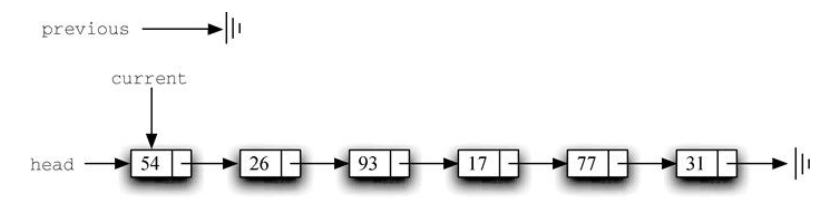
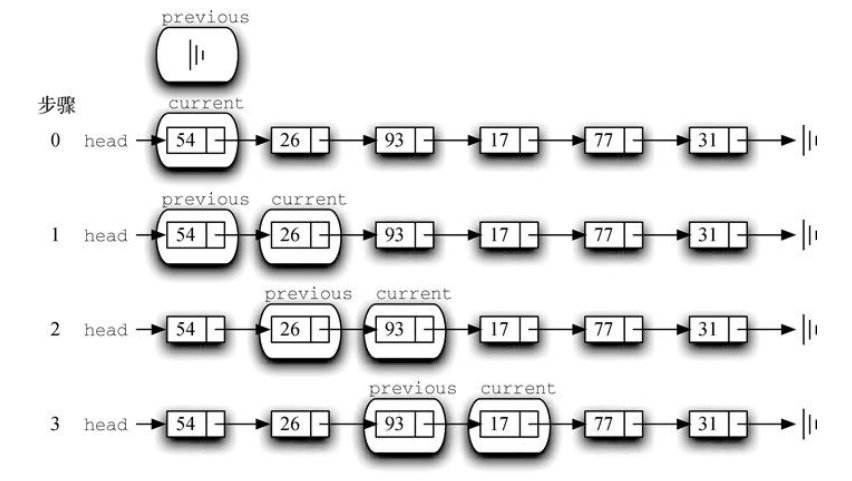
构建链表 。无序列表需要维持元素之间的相对位置,但是并不需要在连续的内存空间中维护这些位置信息。
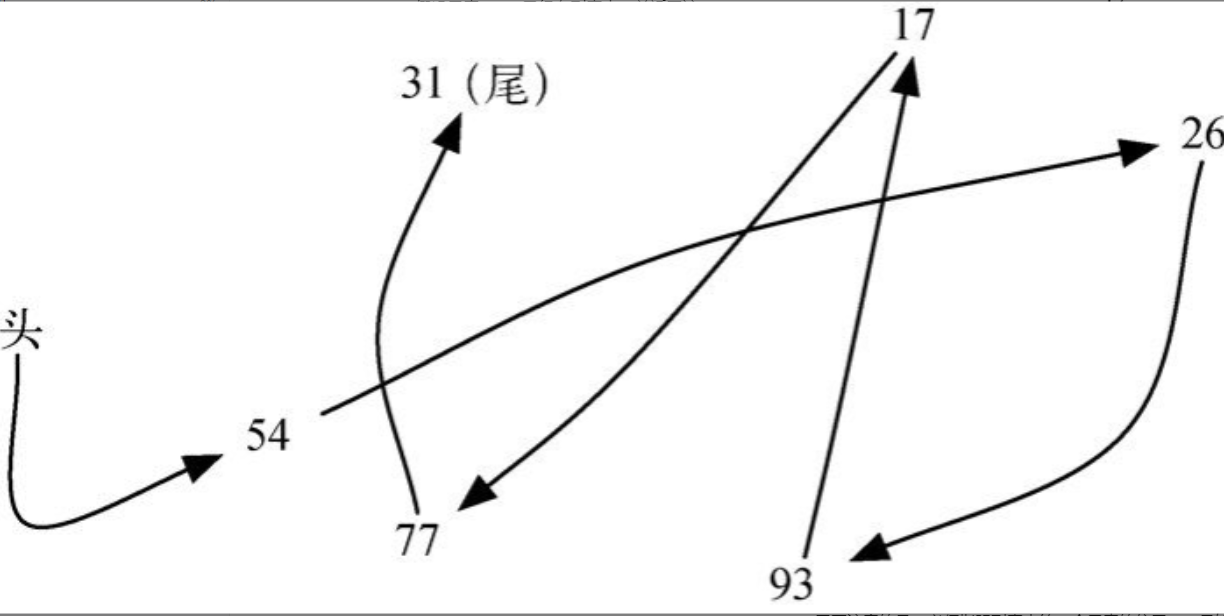
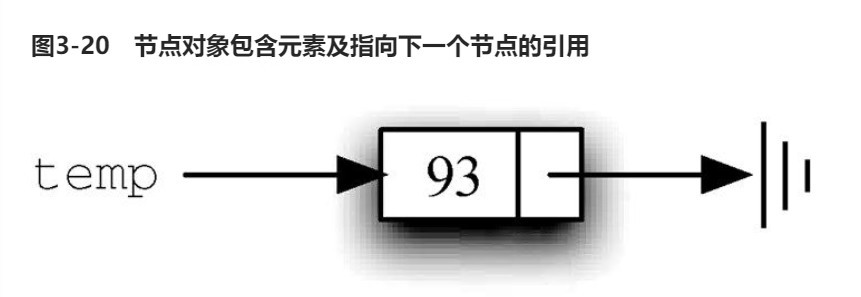
必须指明列表中第一个元素的位置。一旦知道第一个元素的位置,就能根据其中的链接信息访问第二个元素,接着访问第三个元素,依此类推。指向链表第一个元素的引用被称作头 。最后一个元素需要知道自己没有下一个元素。
1 | #构建node类,node是链表的基本数据结构,每一个node对象有两份信息:1.列表元素(节点的数据变量)2.节点必须保存指向下一个节点的引用。 |
有序列表的ADT
OrderedList()创建一个空有序列表。它不需要参数,且会返回一个空列表。add(item)假设item之前不在列表中,并向其中添加item,同时保持整个列表的顺序。它接受一个元素作为参数,无返回值。remove(item)假设item已经在列表中,并从其中移除item。它接受一个元素作为参数,并且修改列表。search(item)在列表中搜索item。它接受一个元素作为参数,并且返回布尔值。isEmpty()检查列表是否为空。它不需要参数,并且返回布尔值。length()返回列表中元素的个数。它不需要参数,并且返回一个整数。index(item)假设item已经在列表中,并返回该元素在列表中的位置。它接受一个元素作为参数,并且返回该元素的下标。pop()假设列表不为空,并移除列表中的最后一个元素。它不需要参数,且会返回一个元素。pop(pos)假设在指定位置pos存在元素,并移除该位置上的元素。它接受位置参数,且会返回一个元素。
python实现有序列表
其中每个元素都有一个明确的位置。它们通常用于存储和访问按特定顺序排序的数据。
1 | class OrderedList: |